
#3 Best Data Architecture need for modern applications
Data architecture is a critical component of the enterprise applications, data does not leads to only information and knowledge but it define the business strategy of any organization.

Page Contents
Basics of Data Architecture
Data architecture is a critical component of the enterprise applications, data does not leads to only information and knowledge but it define the business strategy of any organization. It is the basis of providing any service in the digital world. The indicative characteristics of an information system around the data it holds would include:
- Personal and sensitive data
- Large size and large number of datasets
- Interdependent, Complex and diverse
- Dynamic e.g. stock market data
- Unstructured e.g. social media data
- Short and long life data
Because of above diverse characteristics designing the Data architecture is very important and necessary factor while designing enterprise application.
However, before we get into the Architecture, let us talk about what is happening with data in modern days. Why RDBMS limiting its use cases? Why everyone talking about NOSQL? Why everyone talking about BIG data and data analytics? Why data science became a stream for research?
Over the past few decades, we have collected huge amount of data and only some percentage are supposed to be meaningful data people used to fit them in RDBMS but when we realized the potential of ignored, unstructured massive data, World started shifting towards NOSQL, Big data and data analytics. In addition, with advancement of the processing power Speed became one of the key driver to access huge unstructured data.
So, enterprise data architecture of modern days applications is a break from traditional data application where data is disconnected from other application and analytics at the same time.
The enterprise data architecture supports fast data created in a multitude of new endpoints, operationalizes the use of that data in applications, and moves data to a “data lake” where services are available for the deep, long-term storage and analytics needs of the enterprise. The enterprise data architecture can be represented as a data pipeline that unifies applications, analytics, and application interaction across multiple functions, products, and disciplines

Modern Data and databases
Key to understanding the need for an enterprise data architecture is an examination of the “database universe” concept, which illustrates the tight link between the age of data and its value.
Most technologists support data existence in a time continuum. In almost every business, data moves from function to function to inform business decisions at all levels of the organization. While data silos still exist, many organizations are moving away from the practice of dumping data in a database—e.g., Oracle, Postgres, DB2, MSSQL, etc.—and holding it statically for long periods of time before taking action.
Why Architecture Matters
Interacting with fast data is a fundamentally different process than interacting with big data that is at rest, requiring systems that are architected differently. With the correct assembly of components that
reflect the reality that application and analytics are merging, an enterprise data architecture can be built that achieves the needs of both data in motion (fast) and data at rest (big).
Building high-performance applications that can take advantage of fast data is a new challenge. Combining these capabilities with big data analytics into an enterprise data architecture is increasingly becoming table stakes.
Objective of designing Enterprise Data Architecture
The objective of designing the enterprise architecture is to deliver key service delivery value to the Enterprises. The value delivered by investing in designing the architecture can be evaluated using follow
- Cost savings
- Efficiency
- Service quality
- Strategic control
- Availability
To achieve two things emerge as need for today application- FATS & BIG. Enterprise applications should able to process big amount of data and server as fast as possible to achieve the highest output from it.
Here is the reference architecture for Modern application considering the above facts
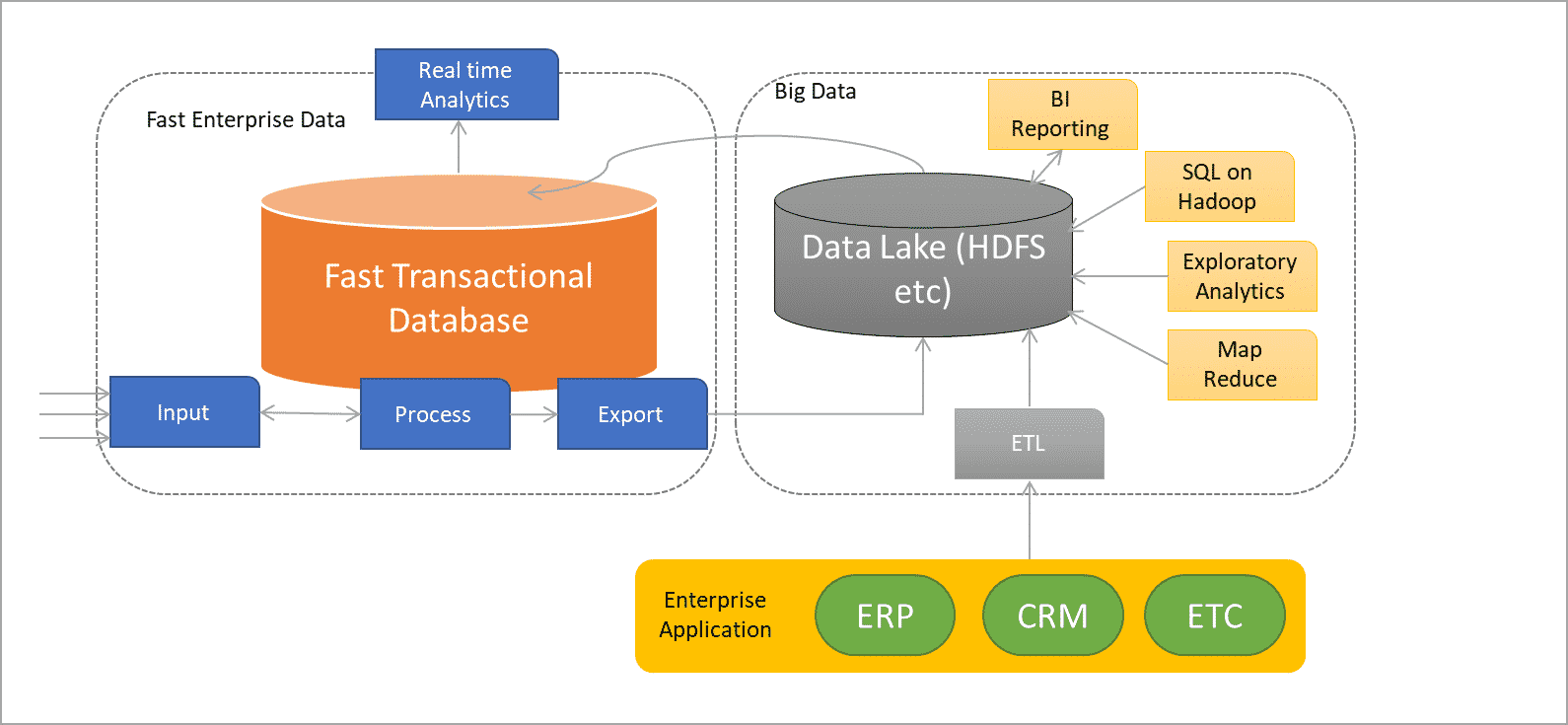
Reference Architecture for Modern Enterprise Application
The first thing to notice is the tight coupling of fast and big, although they are separate systems; they have to be, at least at scale. The database system designed to work with millions of event decisions per second is wholly different from the system designed to hold petabytes of data and generate extensive historical reports.
Big Data, the Enterprise Data Architecture, and the Data Lake
The big data portion of the architecture is centered around a data lake, the storage location in which the enterprise dumps all of its data. This component is a critical attribute for a data pipeline that must capture all information. The data lake is not necessarily unique because of its design or functionality; rather, its importance comes from the fact that it can present an enormously cost-effective system to store everything. Essentially, it is a distributed file system on cheap commodity hardware.
Today, the Hadoop Distributed File System (HDFS) looks like a suitable alternative for this data lake, but it is by no means the only answer. There might be multiple winning technologies that provide solutions to the need.
The big data platform’s core requirements are to store historical data that will be sent or shared with other data management products, and also to support frameworks for executing jobs directly against the data in the data lake.
Necessary components for Enterprise Architecture
- Business intelligence (BI) – reporting
Data warehouses do an excellent job of reporting and will continue to offer this capability. Some data will be exported to those systems and temporarily stored there, while other data will be accessed directly from the data lake in a hybrid fashion. These data warehouse systems were specifically designed to run complex report analytics, and do this well.
- SQL on Hadoop
Much innovation is happening in this space. The goal of many of these products is to displace the data warehouse. These systems have a long way to go to get near the speed and efficiency of data warehouses, especially those with columnar designs. SQLon- Hadoop systems exist for a couple of important reasons:
- SQL is still the best way to query data
- Processing can occur without moving big chunks of data around
- Exploratory analytics
This is the realm of the data scientist. These tools offer the ability to “find” things in data: patterns, obscure relationships, statistical rules, etc.
- Job scheduling
This is a loosely named group of job scheduling and management tasks that often occur in Hadoop. Many Hadoop use cases today involve pre-processing or cleaning data prior to the use of the analytics tools described above. These tools and interfaces allow that to happen.
The big data side of the enterprise data architecture has gained huge attention in Modern Enterprise Applications. Few would debate the fact that Hadoop has sparked the imagination of what is possible when data is fully utilized. However, the reality of how this data will be leveraged is still largely unknown.
Integrating Traditional Enterprise Applications into the Enterprise Data Architecture
The new enterprise data architecture can coexist with traditional applications until the time at which those applications require the capabilities of the enterprise data architecture. They will then be merged
into the data pipeline. The predominant way in which this integration occurs today, and will continue for the foreseeable future, is through an extract, transform, and load (ETL) process that extracts, transforms as required, and loads legacy data into the data lake where everything is stored. These applications will migrate to full-fledged fast + big data modern applications.
Conclusion
It is absolutely necessary to understand the promise and value of fast data but it is not sufficient enough for guaranteed success for enterprise working on implementing Big data initiatives. However, technologies and skillset to take advantage of fast data is necessary and critical for business and enterprises across the globe.
Fast data is a product of Big data, while there are unleashed opportunities from mining the data to derive business insights to enable growth there are much that still need to be accomplished. So by collecting vast amounts of data for exploration and analysis will not prepare a business to act in real time, as data flows into the organization from millions of endpoints: sensors, mobile devices, connected systems, and the Internet of Things.
We have to understand the architectural requirement for both fast and Big data separately and address the challenges with the right tools and technologies. But to take the business advantage we have to architecturally integrate and serve the applications on fast data processed from big data.
For more information refer wiki and explore more at Teknonauts

Awadhesh Pratap Dwivedi is an IT industry leader with over 13+ years of experience. He is excellent at providing an easy solution to complex business problems with his tremendous problem-solving skills. Currently, he is working with Oracle as a Principal Solution Engineer.







TY, great post! Just what I had to know. http://www.piano.m106.com
Thanks for the comment, Keep looking for more blogs. we will continue writing and making videos. do subscribe also our YouTube channel.